Extract summary from ulsif object, including two-sample significance test for homogeneity of the numerator and denominator samples
Source: R/summary.R
summary.ulsif.RdExtract summary from ulsif object, including two-sample significance
test for homogeneity of the numerator and denominator samples
Usage
# S3 method for class 'ulsif'
summary(
object,
test = FALSE,
n_perm = 100,
parallel = FALSE,
cluster = NULL,
...
)Arguments
- object
Object of class
ulsif- test
logical indicating whether to statistically test for homogeneity of the numerator and denominator samples.
- n_perm
Scalar indicating number of permutation samples
- parallel
logicalindicating to run the permutation test in parallel- cluster
NULLor a cluster object created bymakeCluster. IfNULLandparallel = TRUE, it uses the number of available cores minus 1.- ...
further arguments passed to or from other methods.
Examples
set.seed(123)
# Fit model
dr <- ulsif(numerator_small, denominator_small)
# Inspect model object
dr
#>
#> Call:
#> ulsif(df_numerator = numerator_small, df_denominator = denominator_small)
#>
#> Kernel Information:
#> Kernel type: Gaussian with L2 norm distances
#> Number of kernels: 150
#> sigma: num [1:10] 0.711 1.08 1.333 1.538 1.742 ...
#>
#> Regularization parameter (lambda): num [1:20] 1000 483.3 233.6 112.9 54.6 ...
#>
#> Optimal sigma (loocv): 3.425852
#> Optimal lambda (loocv): 0.6951928
#> Optimal kernel weights (loocv): num [1:150] 0.05072 0.09115 0.07853 0.10771 -0.00969 ...
#>
# Obtain summary of model object
summary(dr)
#>
#> Call:
#> ulsif(df_numerator = numerator_small, df_denominator = denominator_small)
#>
#> Kernel Information:
#> Kernel type: Gaussian with L2 norm distances
#> Number of kernels: 150
#>
#> Optimal sigma: 3.425852
#> Optimal lambda: 0.6951928
#> Optimal kernel weights: num [1:150] 0.05072 0.09115 0.07853 0.10771 -0.00969 ...
#>
#> Pearson divergence between P(nu) and P(de): 0.3872
#> For a two-sample homogeneity test, use 'summary(x, test = TRUE)'.
#>
# Plot model object
plot(dr)
#> Warning: Negative estimated density ratios for 7 observation(s) converted to 0.01 before applying logarithmic transformation
#> `stat_bin()` using `bins = 30`. Pick better value `binwidth`.
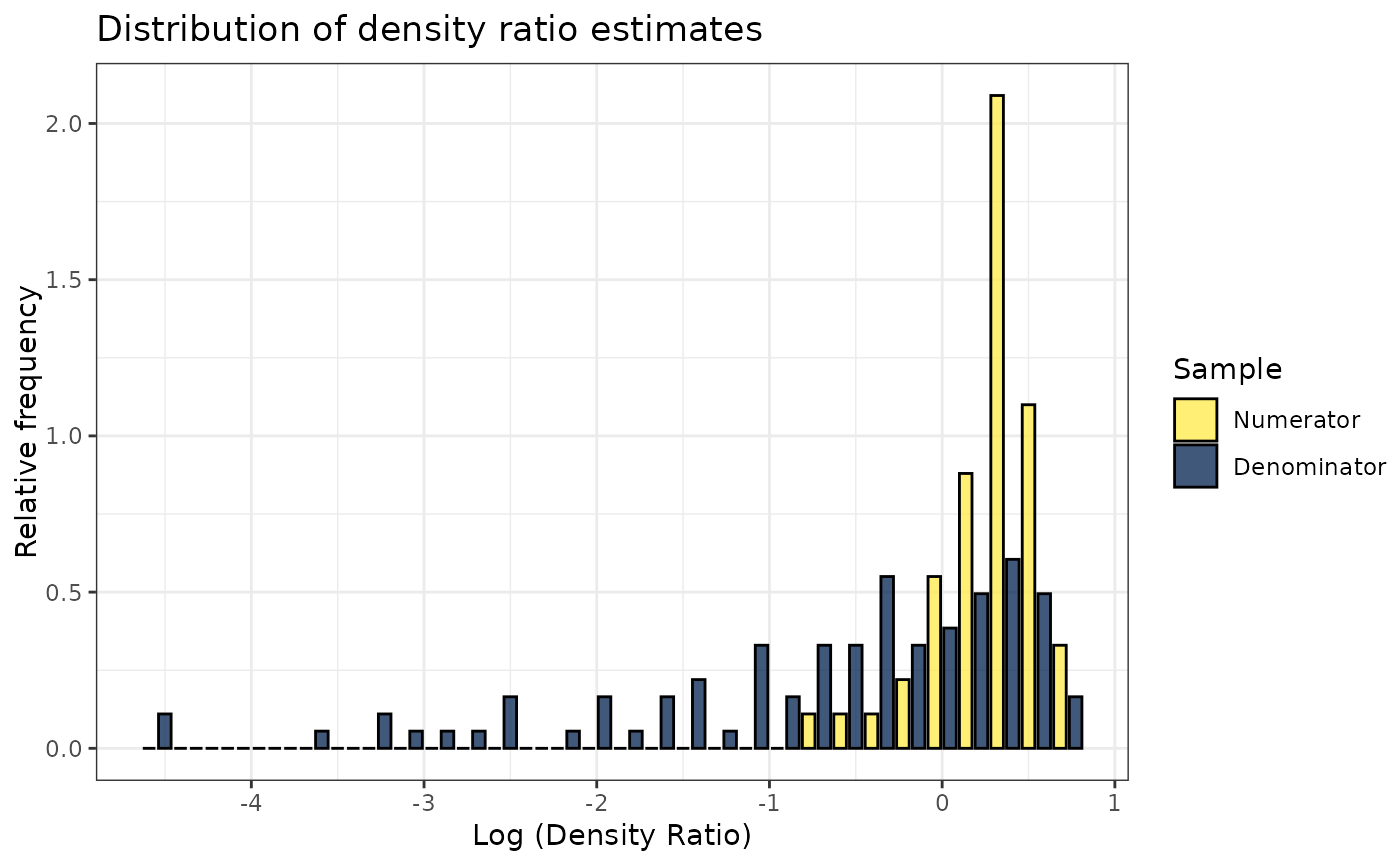 # Plot density ratio for each variable individually
plot_univariate(dr)
#> Warning: Negative estimated density ratios for 7 observation(s) converted to 0.01 before applying logarithmic transformation
#> [[1]]
# Plot density ratio for each variable individually
plot_univariate(dr)
#> Warning: Negative estimated density ratios for 7 observation(s) converted to 0.01 before applying logarithmic transformation
#> [[1]]
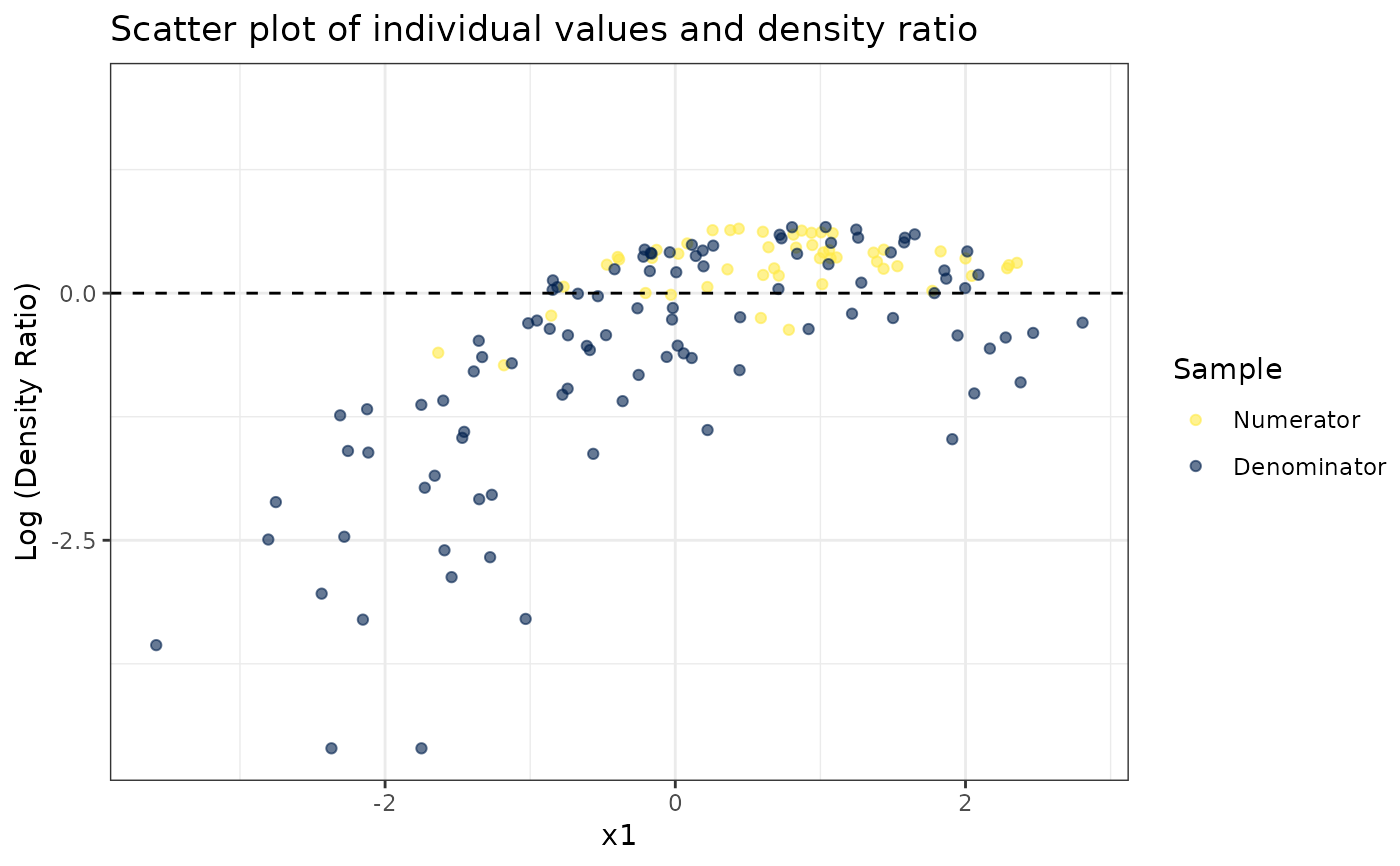 #>
#> [[2]]
#>
#> [[2]]
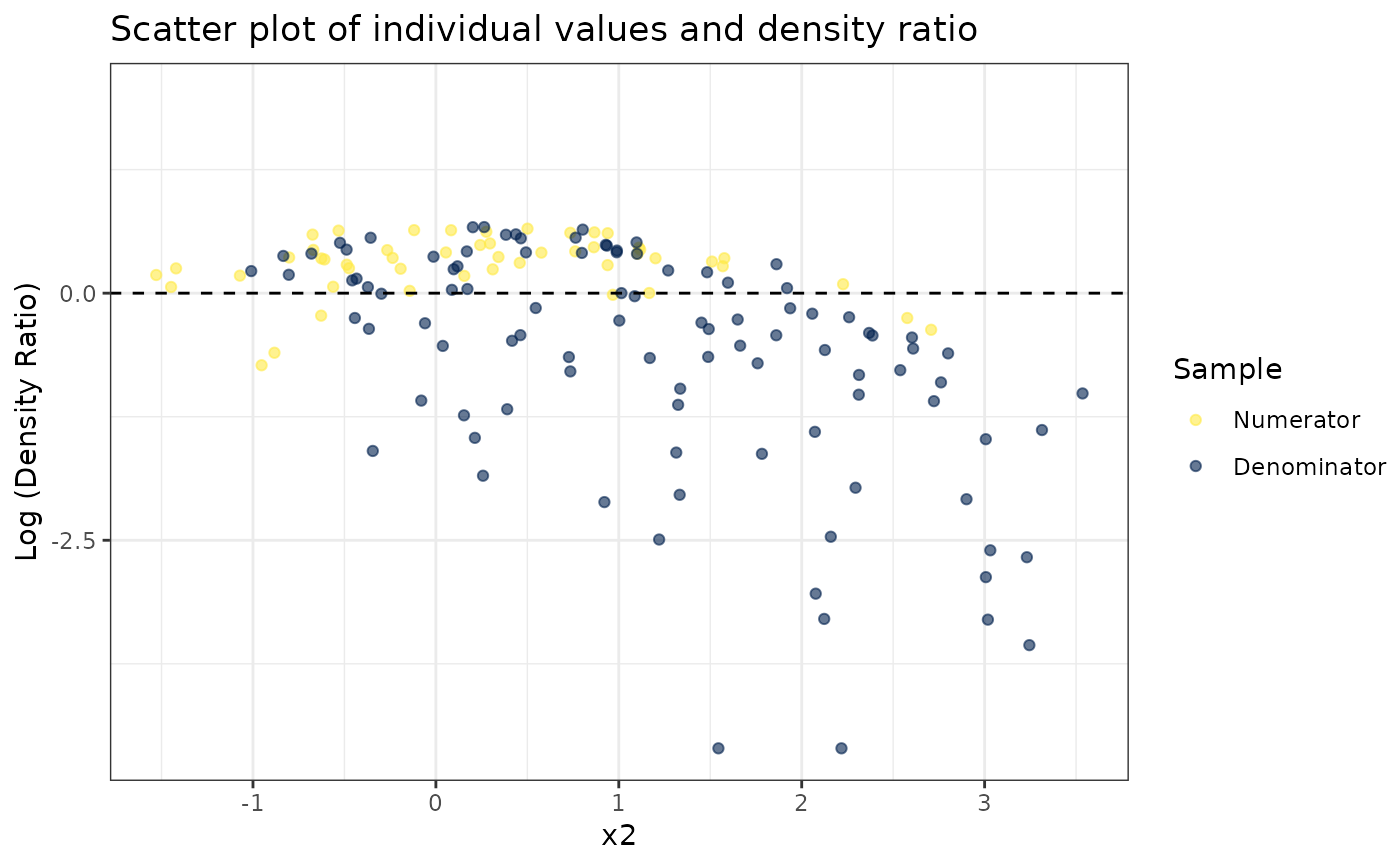 #>
#> [[3]]
#>
#> [[3]]
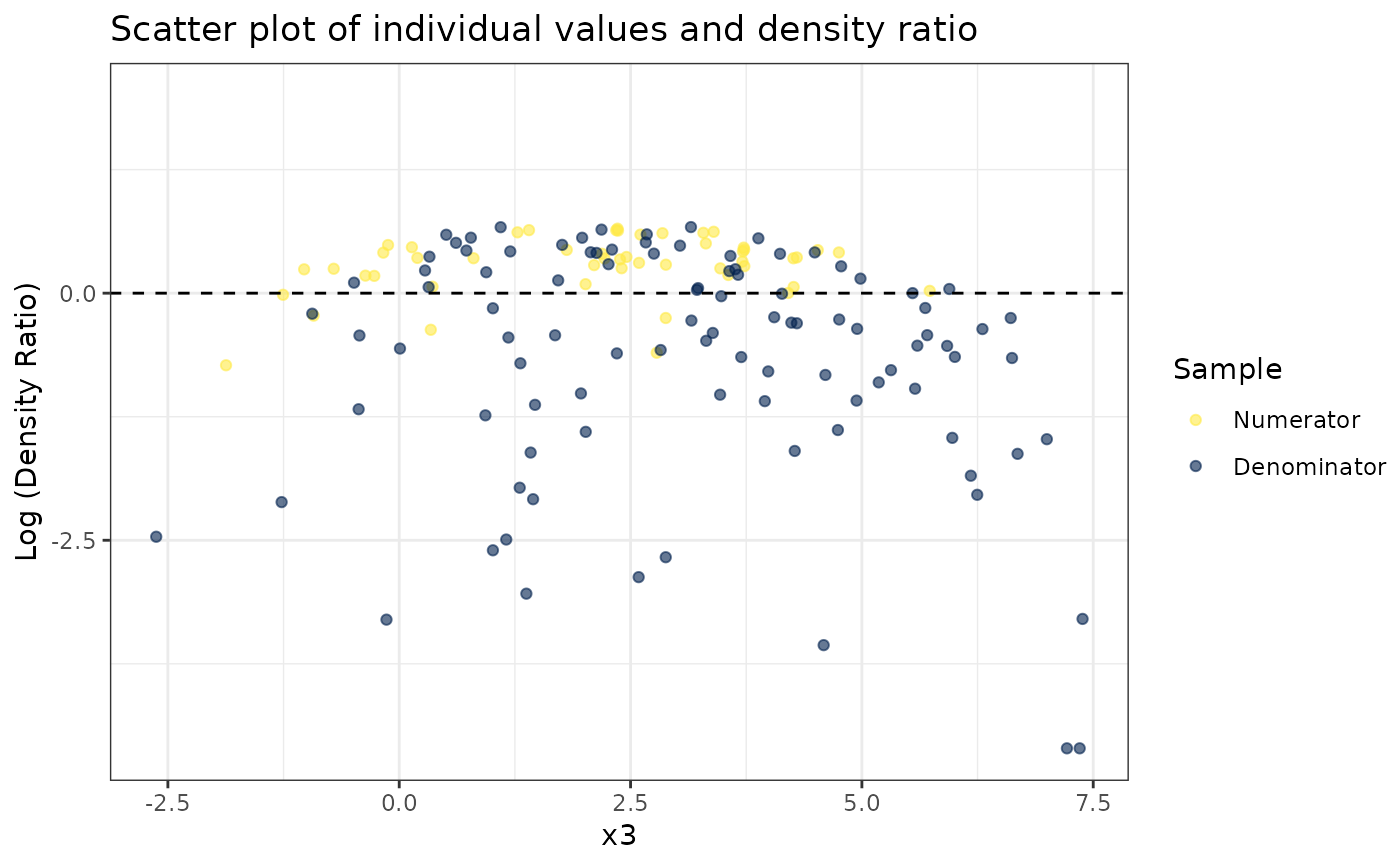 #>
# Plot density ratio for each pair of variables
plot_bivariate(dr)
#> Warning: Negative estimated density ratios for 7 observation(s) converted to 0.01 before applying logarithmic transformation
#> [[1]]
#>
# Plot density ratio for each pair of variables
plot_bivariate(dr)
#> Warning: Negative estimated density ratios for 7 observation(s) converted to 0.01 before applying logarithmic transformation
#> [[1]]
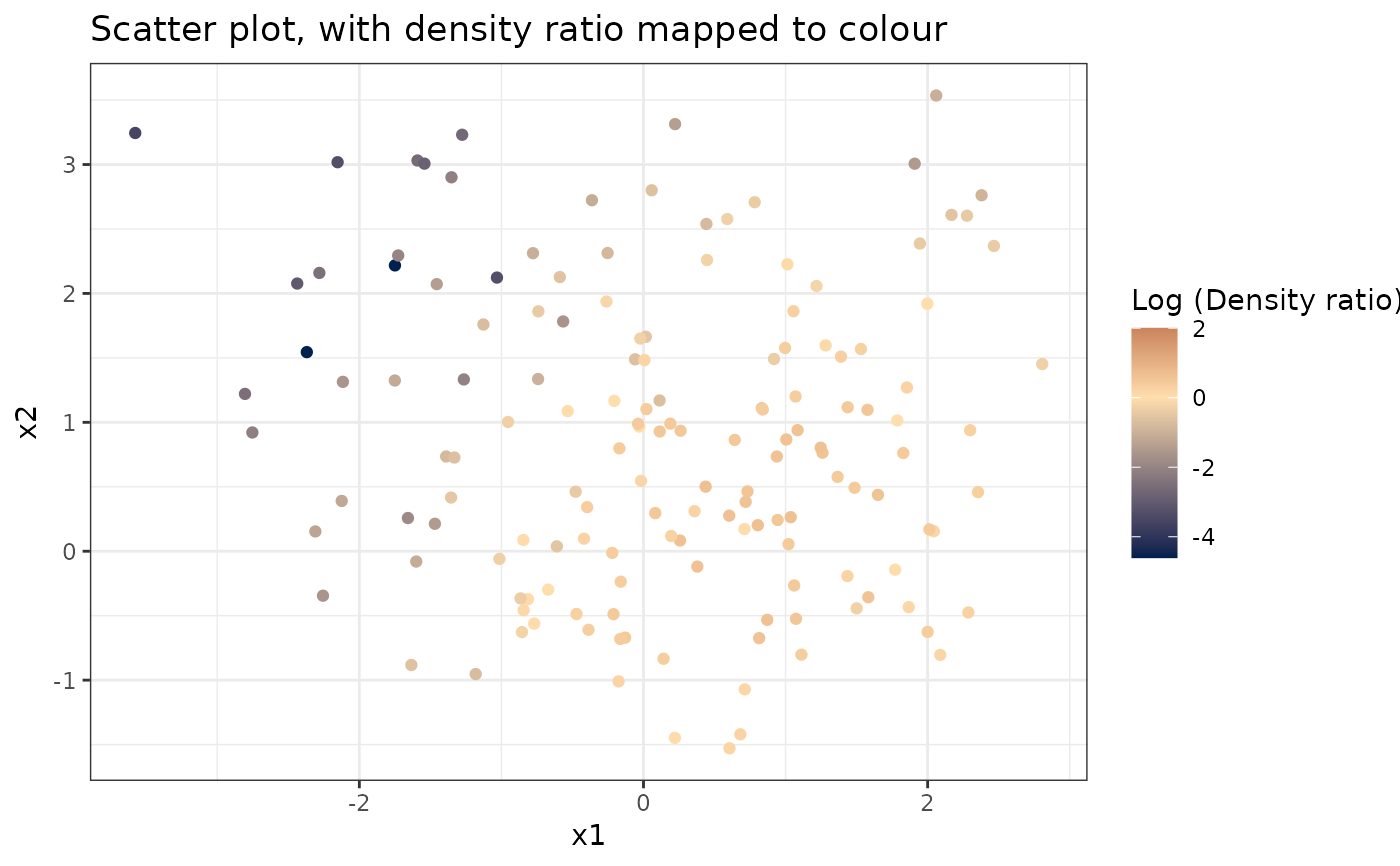 #>
#> [[2]]
#>
#> [[2]]
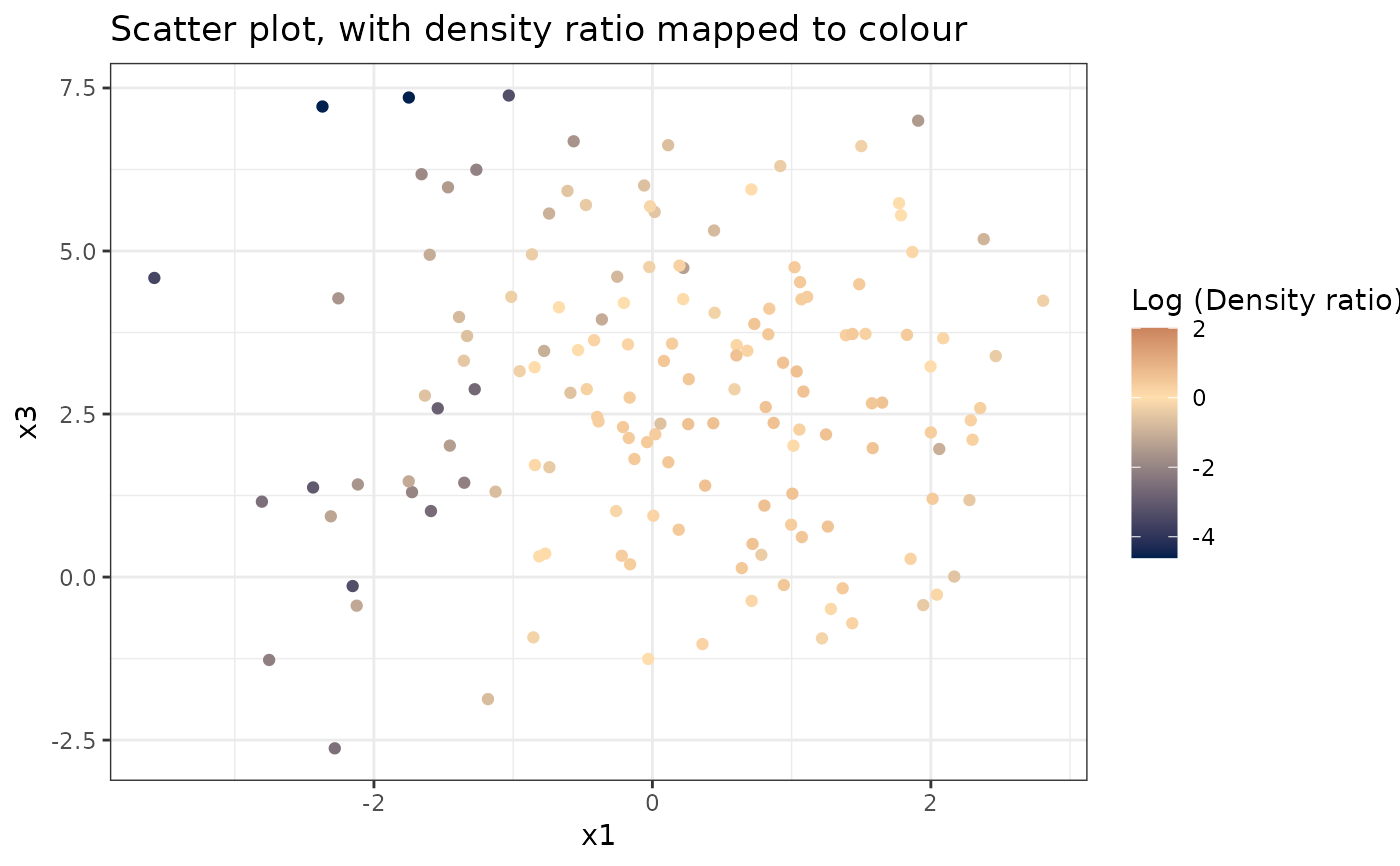 #>
#> [[3]]
#>
#> [[3]]
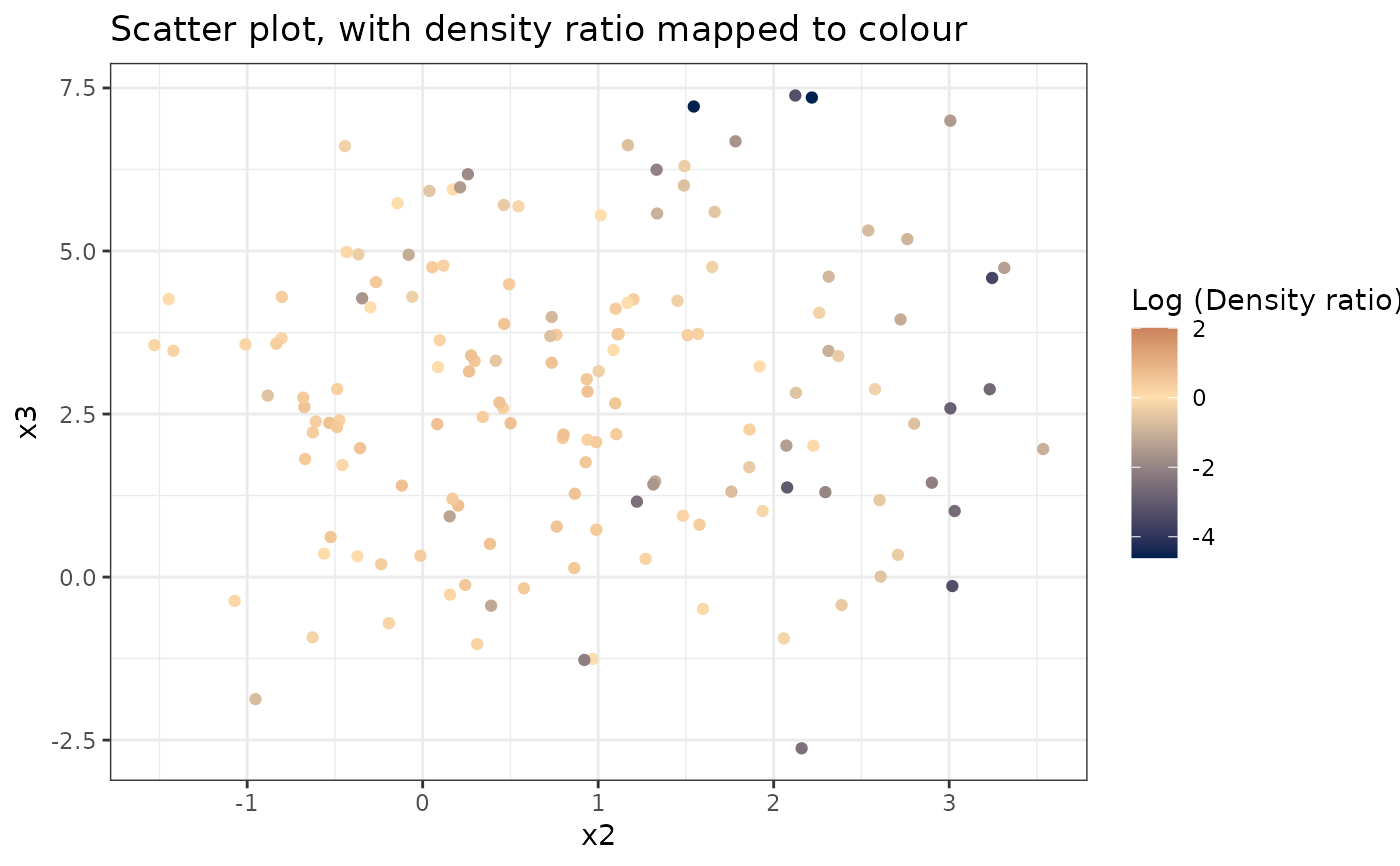 #>
# Predict density ratio and inspect first 6 predictions
head(predict(dr))
#> , , 1
#>
#> [,1]
#> [1,] 1.637268
#> [2,] 2.230380
#> [3,] 2.147449
#> [4,] 2.302901
#> [5,] 1.228723
#> [6,] 1.785768
#>
# Fit model with custom parameters
ulsif(numerator_small, denominator_small, sigma = 2, lambda = 2)
#>
#> Call:
#> ulsif(df_numerator = numerator_small, df_denominator = denominator_small, sigma = 2, lambda = 2)
#>
#> Kernel Information:
#> Kernel type: Gaussian with L2 norm distances
#> Number of kernels: 150
#> sigma: num 2
#>
#> Regularization parameter (lambda): num 2
#>
#> Optimal sigma (loocv): 2
#> Optimal lambda (loocv): 2
#> Optimal kernel weights (loocv): num [1:150] 0.0353 0.0558 0.0534 0.0622 0.0111 ...
#>
#>
# Predict density ratio and inspect first 6 predictions
head(predict(dr))
#> , , 1
#>
#> [,1]
#> [1,] 1.637268
#> [2,] 2.230380
#> [3,] 2.147449
#> [4,] 2.302901
#> [5,] 1.228723
#> [6,] 1.785768
#>
# Fit model with custom parameters
ulsif(numerator_small, denominator_small, sigma = 2, lambda = 2)
#>
#> Call:
#> ulsif(df_numerator = numerator_small, df_denominator = denominator_small, sigma = 2, lambda = 2)
#>
#> Kernel Information:
#> Kernel type: Gaussian with L2 norm distances
#> Number of kernels: 150
#> sigma: num 2
#>
#> Regularization parameter (lambda): num 2
#>
#> Optimal sigma (loocv): 2
#> Optimal lambda (loocv): 2
#> Optimal kernel weights (loocv): num [1:150] 0.0353 0.0558 0.0534 0.0622 0.0111 ...
#>