Synthetic data
Enhancing open and reproducible social science while protecting participants’ privacy
Utrecht University & Statistics Netherlands
Open data is the pinnacle of open science
- Transparency (with analysis code)
- Learning from colleagues
- Potential for follow-up analyses
- Eases research synthesis
But when the data is sensitive, openly disseminating research data is not possible.
When open data is not allowed …
Data is simply not available, bye!
“Data is available upon reasonable request.”
Data is on a secure server with data access procedures.
About me
Thom Benjamin Volker
- Utrecht University & Statistics Netherlands
- PhD. Candidate in Methodology and Statistics
Research interests: methods to enhance data privacy, synthetic data and multiple imputation of missing data.
About me
Thorben van Meij-Kolm
- DSM-Firmenich
- Data scientist
Research interests: forecasting, A/B testing.
Synthetic data
Synthetic data is data that is generated from a statistical model, as opposed to real, collected data
Fake data, generated data, digital twins
The goal of synthetic data
Capture the most important information about the data in a model
Generate new samples from this model
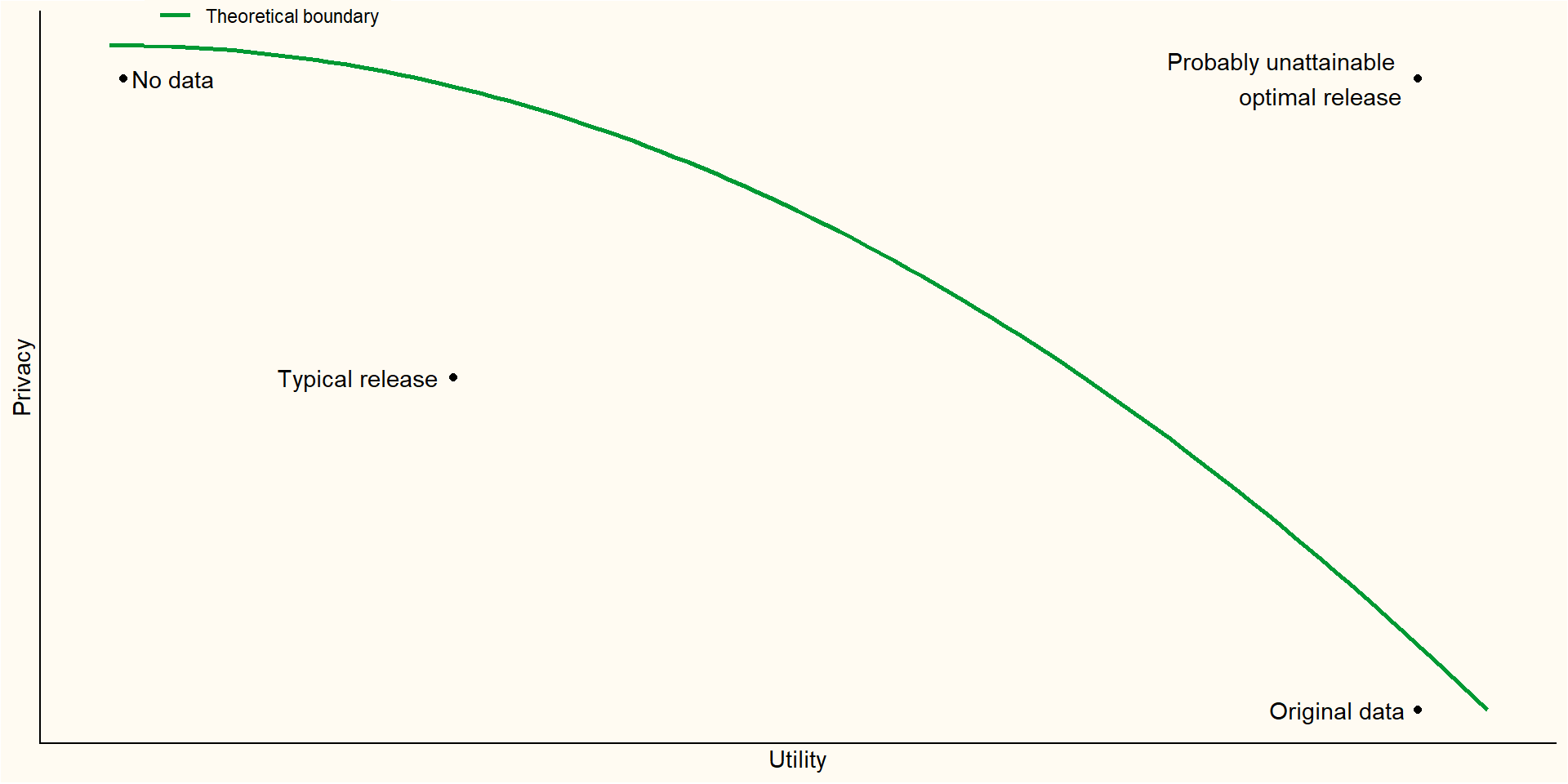
The privacy-utility trade-off
![]()
Is anonymizing not enough?
If done well, anonymization might suffice.
But: data might be linked in suprising ways.
With enough variables, every record becomes unique.
Narayanan & Shmatikov (2008) identified 99% of the records in the (anonymized!) Netflix Prize Data based on some crude information
Advantages of synthetic data
Privacy can be well protected
A large amount of information can be preserved
- Important information can be modelled explicitly
Disadvantages
Quality of synthetic data depends entirely on synthesis model
Generating synthetic data
Privacy risk assessment
What’s the goal of the synthetic data?
Choosing the synthetic data model
Evaluating risk and utility
Refinements necessary?
Privacy risk assessment
Anonymization: remove directly identifying information.
Names, ID numbers, addresses, user ID’s
Often unique and hard to synthesize
Evaluate outliers: might be directly identifying
Identify sensitive variables: consider recoding and coarsening
What should be achievable with the synthetic data?
Dummy data?
Teaching?
Replication?
Novel research?
Is the real data eventually available in a secure environment?
Generating synthetic data
You need a generative model
\[
f(D_{syn}|\theta)
\]
You require an (implicit or explicit) model \(f\) for the data \(D\) with parameters \(\theta\)
Parameters are typically learned from real data; as opposed to simulated data.
Don’t you ever!
![]()
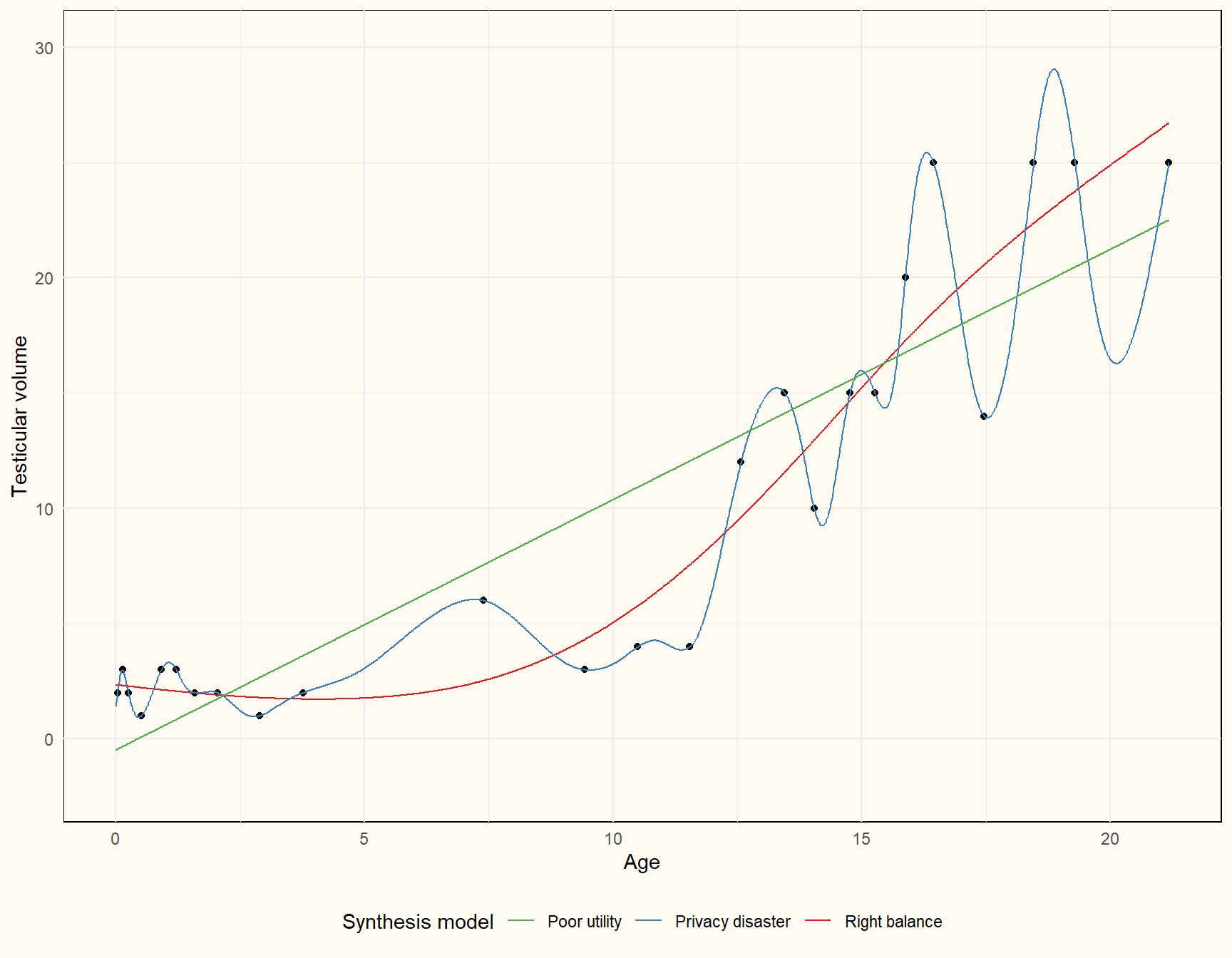
Choosing a synthetic data model
What information do you want to preserve?
The privacy-utility trade-off once again
![]()
Generating dummy data
Synthesize univariately
Easy to bound information that goes into synthesis model
Limited fidelity, but can be highly useful still!
E.g., getting familiar with the data, code checking, model building, script writing (code to data procedures)
High-fidelity synthetic data
Conditional modelling versus joint modelling
Parametric versus non-parametric learning
Fully versus partially synthetic data
Differential privacy
Bounds the maximum influence a single individual can have on a model
Adds noise such that the results are almost equivalent regardless of whether this maximally influential individual was present in the data
Often performs poorly for conservative values of the privacy parameter
Non-parametric joint modelling
Often based on deep-learning or copulas
Superior for structured data (images, geo-spatial data, fMRI)
Hard to know and communicate what information ends up in the synthetic data
Software: Synthetic Data Vault (sdv), synthcity (python); RGAN
Conditional modelling
Building one model per variable is often easier (conceptually) and provides a lot of flexibility
Model checking (posterior predictive checks)
Easier to make refinements
More obvious what information ends up in synthetic data
Software: synthpop (R, python still in development)
Evaluating privacy risk
Identity disclosure: can we infer whether a particular individual was part of a data
- Usually not a big deal, unless identifying are also sensitive (e.g., extremely large incomes are reproduced)
Attribute disclosure: characteristics about individuals can be learned with near certainty
- E.g., all records with the same set of identifying characteristics also share a common sensitive attribute
Privacy risks are often more a property of the synthesis method
Evaluating synthetic data utility
Fit-for-purpose
Analysis-specific utlity
Global utility
Fit for purpose measures
Similar variable types, no impossible values, similar scales
Evaluate by inspecting the data and making visualizations
- Histograms
- Density plots
- Summary statistics
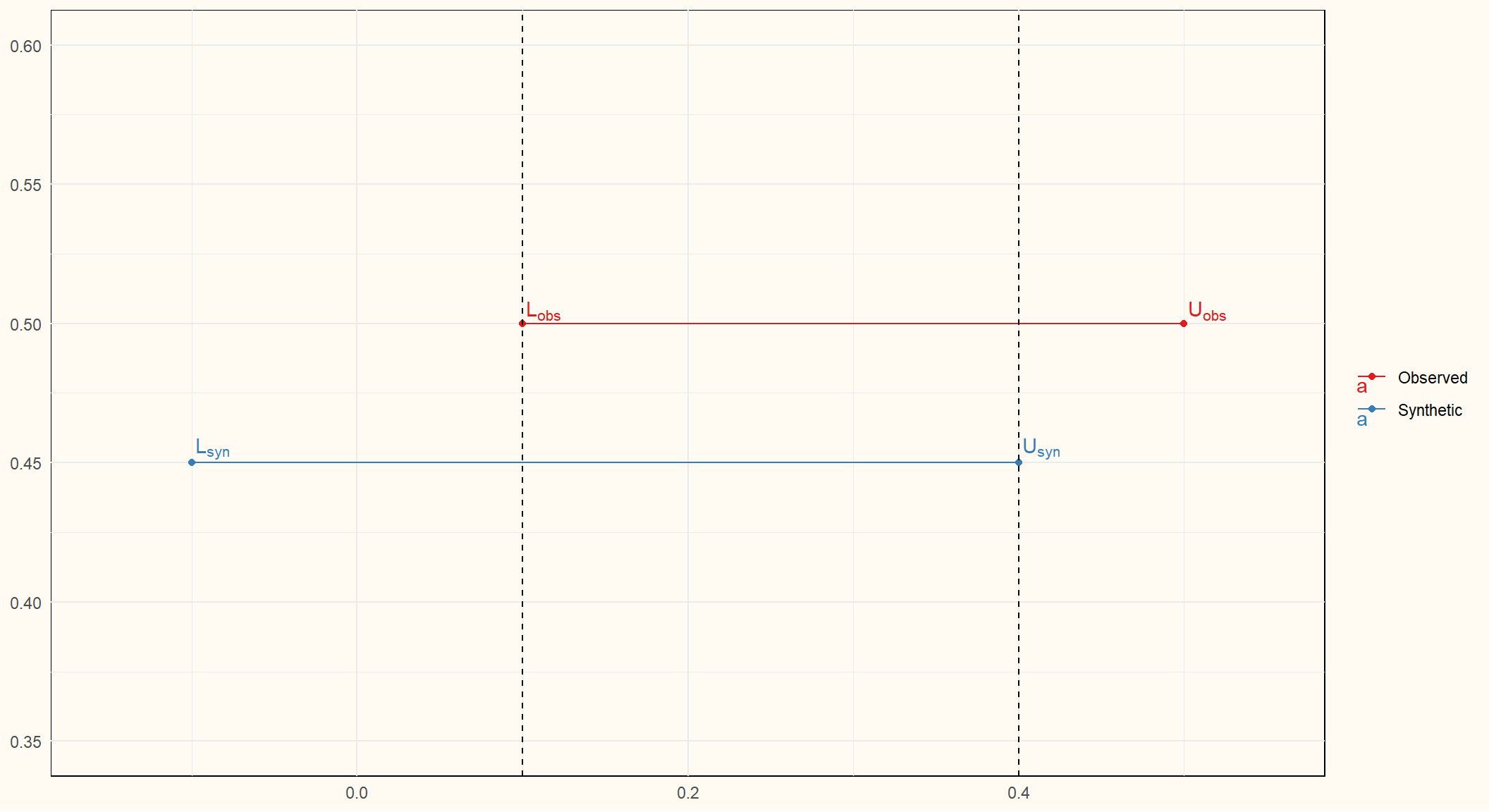
Analysis specific utility
Do analyses on observed and synthetic data yield similar results?
Compare estimates; confidence interval overlap
![]()
Global utility measures
Where do the observed and synthetic data distributions diverge?
Density ratio (with densityratio R-package) \[
r(\mathbf{x}) = \frac{p_{obs}(\mathbf{x})}{p_{syn}(\mathbf{x})}
\]
Classifier-based testing: can we predict which values are real and which are synthetic?
Publishing synthetic data
Put privacy over utility!
Make clear the data is synthetic: filename, title, description, variable names?
Be as explicit as possible about how the data is generated and what can and cannot be done with it.