Prediction intervals with missing data
Department of Methodology and Statistics, Utrecht University
Uncertainty quantification
Proper uncertainty quantification is essential in prediction settings
- Expected grade
- Election polling
- Package delivery

Evaluation (simulation)
Linear regression model: \(y = X\beta + \varepsilon\)
\(X \sim MVN(0, \Sigma)\)
MAR missingness in train, test or both
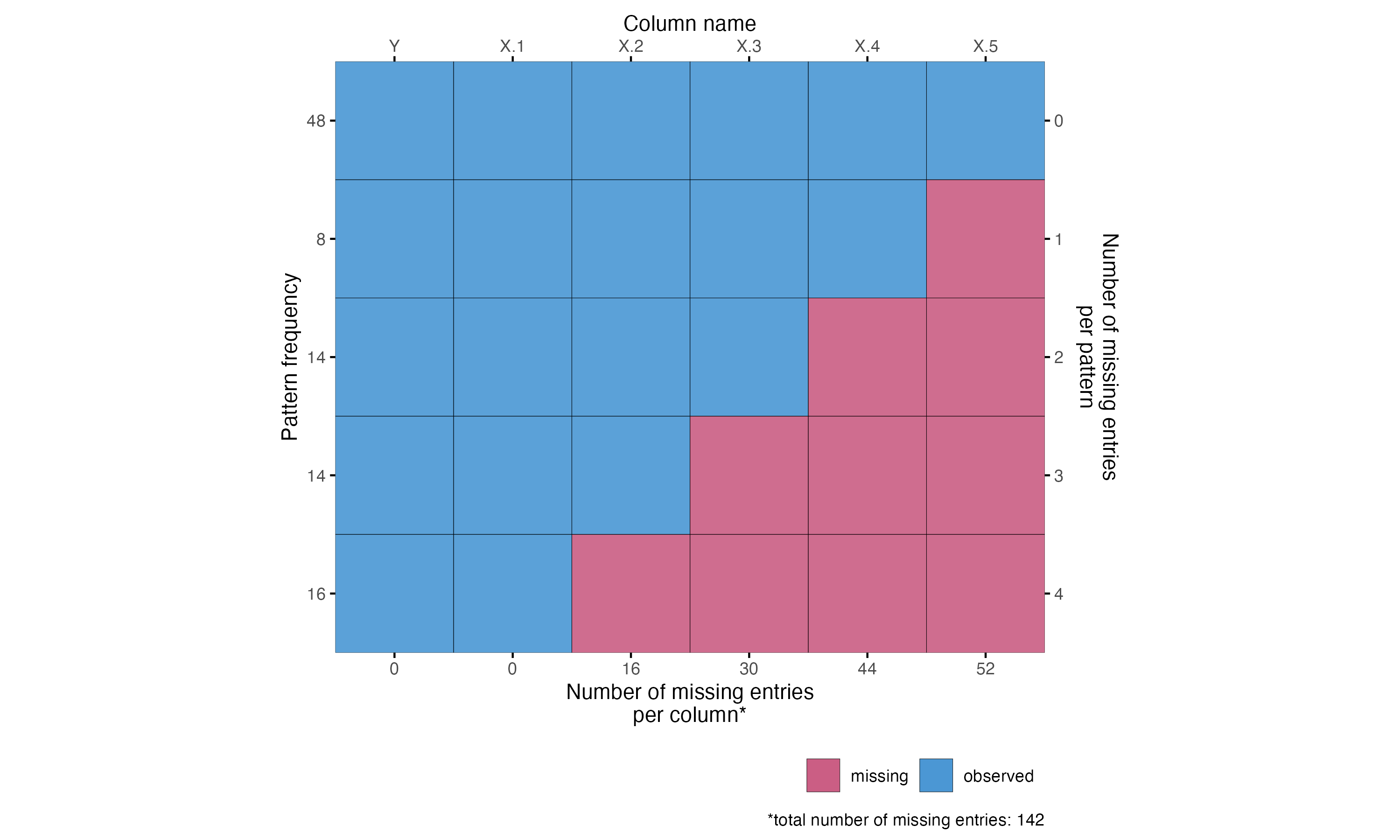
Varied sample size, correlation
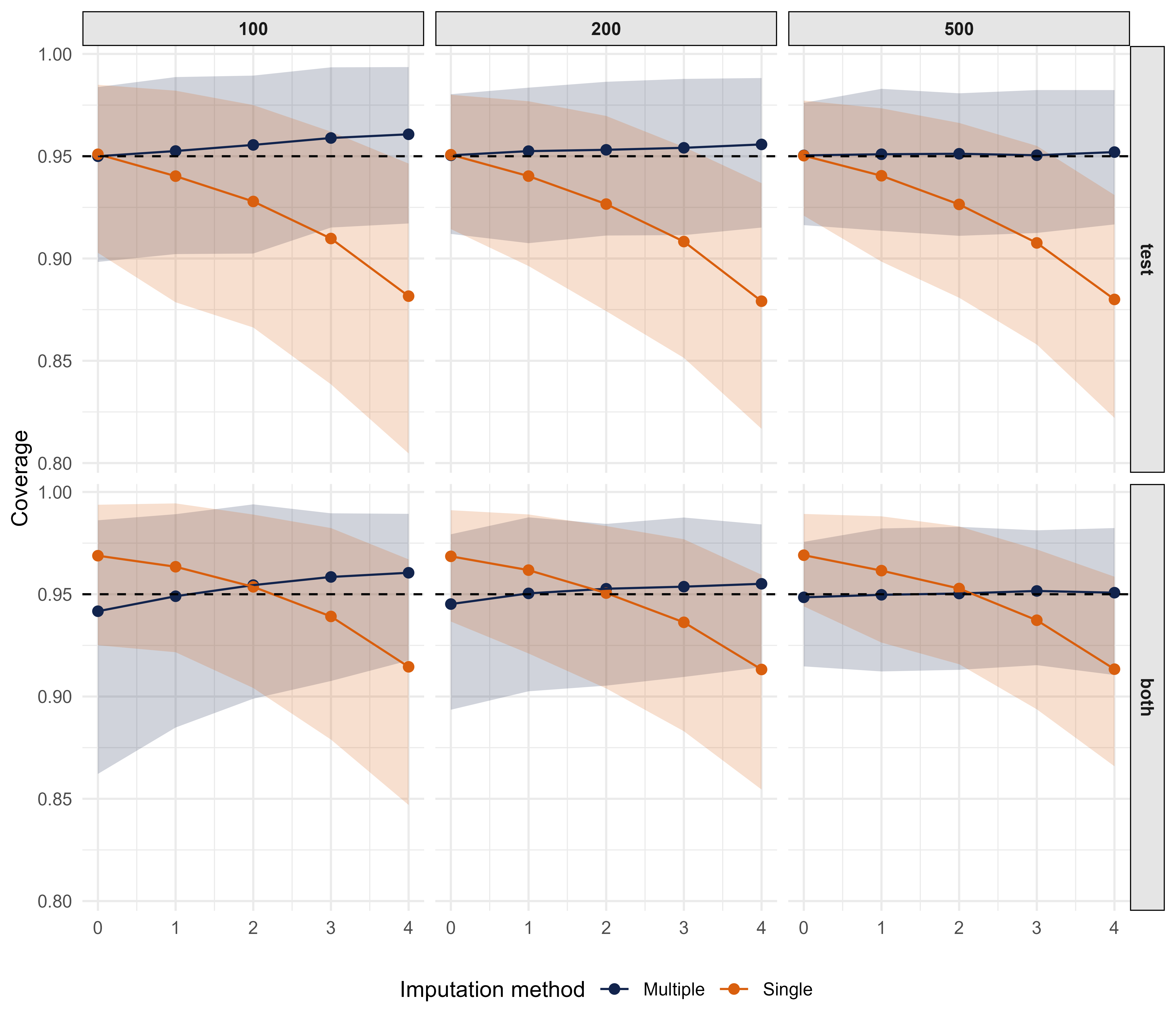
Marginal coverage results
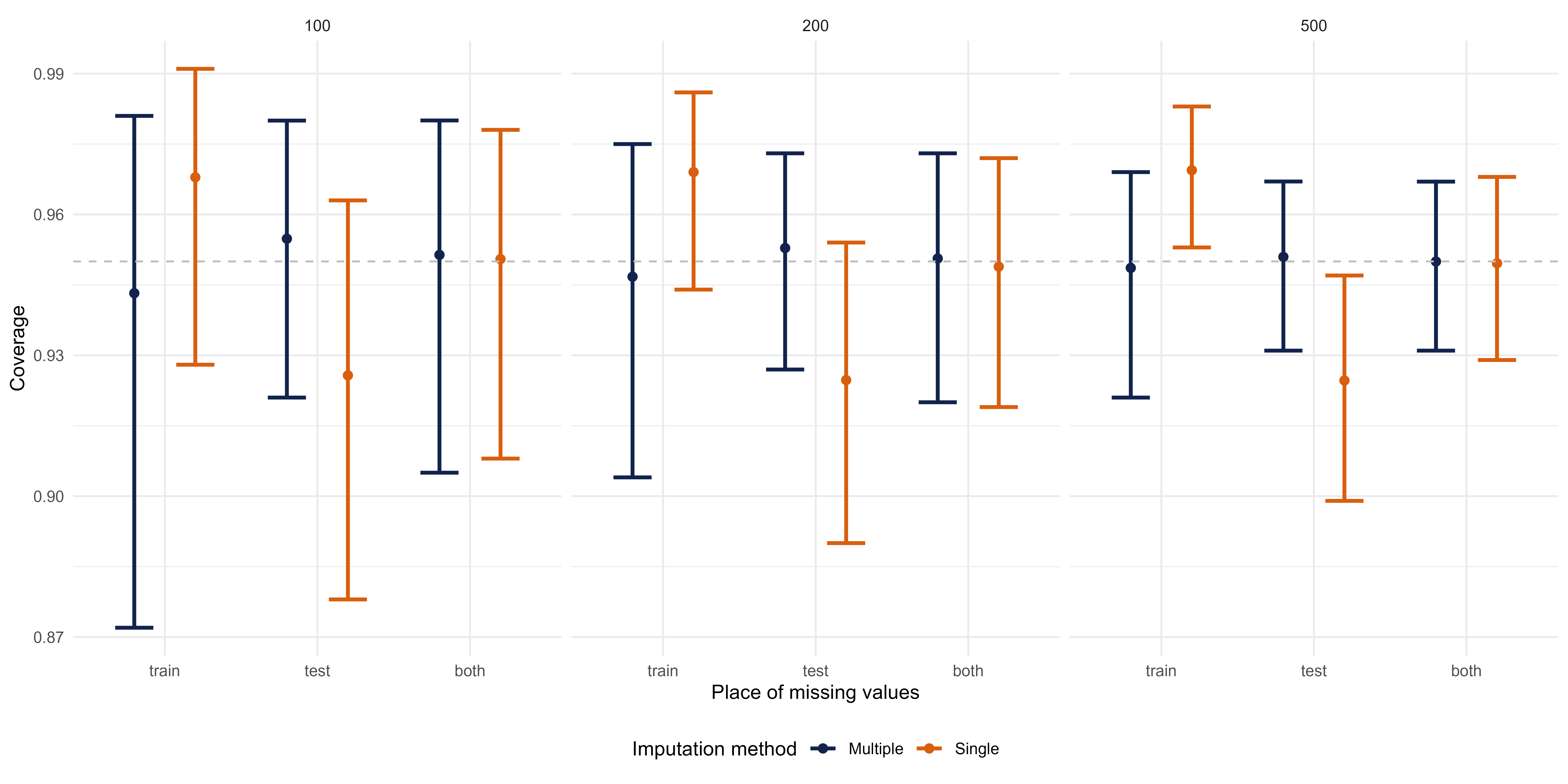
Marginal coverage (y-axis) for multiple and single imputation, depending on whether missingness occurs only in the training data, only in the test data, or in both, for different sizes of the training data.
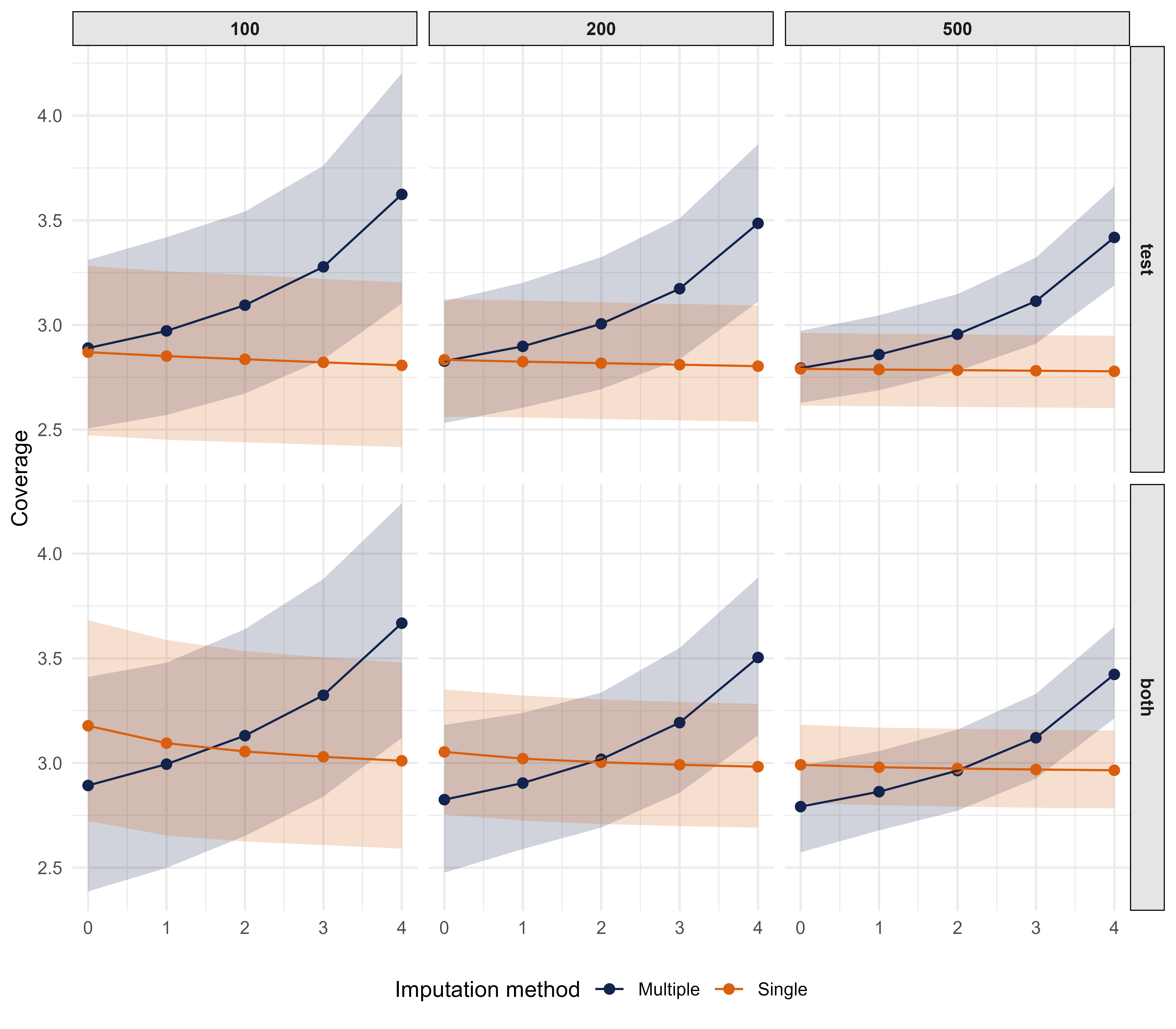
Conditional coverage results